
Release:2025.11.13 Update:2025.11.13
はじめに
2025年7月に発信したプレスリリースでは、ヤマシタにおけるDifyの導入背景と、AIコーチングbotの開発についてご紹介しました。あれから数ヶ月、デジタル本部では2030年ビジョンの実現に向けた技術検証を進めています。
現在、AIコーチングbotだけでなく、人事領域や業務効率化など、様々な用途に特化したbotが次々と開発されています。これらの取り組みを通じて、私たちは一つの重要な課題に直面しました。それが「音声によるAI活用」です。
本記事では、デジタル本部でDXシニアマネージャーを務める道越が、ヤマシタが取り組む音声AI技術検証の第一弾として、音声入力がもたらす可能性と、私たちが直面している技術的課題についてご紹介します。今後、シリーズとして具体的な実装手法や検証結果を継続的に発信していく予定です。
2030年ビジョンと音声入力の必然性
ヤマシタの2030年ビジョンでは、マルチモーダルAI、特に音声入力の重要性を明確に位置づけています。
なぜ音声なのか?それは私たちの業務現場を考えれば明らかです。
- 営業担当者は、出先での商談や移動中に情報を必要とします。スマートフォンで文字入力してLLMとやり取りすることには限界があります。

- リネンサプライの現場スタッフ(ドライバー等)は、両手が塞がった状態で業務を行うことが多々あります。

このような状況下で、PCやスマートフォンを操作しながらAIを活用するのは、安全面でも効率面でも現実的ではありません。
さらに、音声入力にはテキスト入力にはない優位性もあります。AIに質問や指示を出す際、テキストで論理的に文章を組み立てたり、長文を入力したりするのは意外と時間がかかります。一方、音声なら思いついたことを自然に話すだけで入力が完了します。この手軽さは、AI活用のハードルを大きく下げる要素となります。
TTS(Text-to-Speech:テキスト読み上げ)とSTT(Speech-to-Text:音声認識)を活用し、AIと自然に会話できる環境を整えることが、全社的なAI活用の加速には不可欠なのです。
Difyの限界と新たな挑戦
しかし、ここで一つの技術的な壁に突き当たりました。
Dify単体では、完全な音声モードを実現することが難しいのです。Difyは強力なワークフローエンジンとLLMの統合基盤ですが、音声入出力のインターフェースは別途構築する必要があります。
この課題を解決するため、私たちは新たな技術検証をスタートさせました。
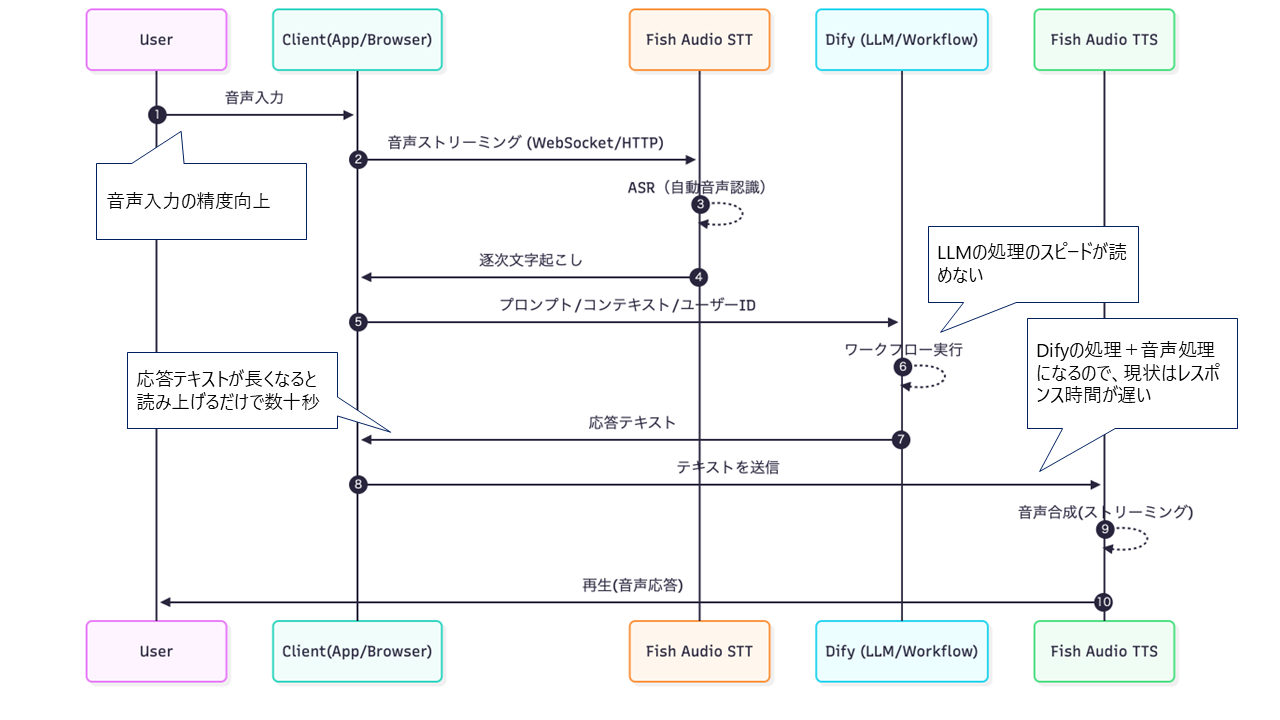
FishAudioとDifyの統合検証
現在取り組んでいるのが、FishAudioなどの音声モデルとDifyの統合です。
仕組みとしては以下のようなフローを想定しています:
- 音声入力(STT): FishAudioで音声をテキスト化
- 処理: Difyのワークフローが動作し、適切な回答を生成
- 音声出力(TTS): 生成されたテキストを音声でフィードバック
このシンプルに見える仕組みですが、実際に実装してみると、様々な技術的課題が浮き彫りになりました。
技術的な挑戦
現在、以下のような技術的な検証と改善に取り組んでいます。
- 低遅延化の実現
音声での会話において、レスポンスの遅延は致命的です。ストリーミング処理の最適化や、処理パイプラインの改善を進めています。
- 音声に適したプロンプト設計
文字で読む場合と音声で聞く場合では、情報の受け取り方が大きく異なります。
- 簡潔で分かりやすい表現
- 音声で聞いたときの理解しやすさ
- 適切な情報量のバランス
これらを考慮したプロンプトのカスタマイズが必要です。
- チャンクの切り方
音声生成時のテキストのチャンク分割も重要な要素です。自然な話し方を実現するため、文脈を考慮した最適な分割方法を模索しています。
今後の展開
この技術検証は、まだ始まったばかりです。現時点では、人とAIの音声ベースでの対話において、STT⇒LLM処理⇒TTS⇒音声モデルが発話するという一連の処理のパフォーマンス課題に直面しています。
また、検証を進める中で見えてきたのは、音声出力の限界でもあります。ディスプレイを見ることができない特殊な環境を除くと、音声を読み上げられるのを待つより、テキストで一気に閲覧する方が効率的なケースも多くあります。例えばスマホでスクロールが不要な文字数であっても、数十秒テキストの読み上げを待たねばならないのは、かえって非効率です。
そのため、用途に応じて音声とテキストを使い分けられるハイブリッドなインターフェースの検討も重要だと考えています。
今後、以下のような内容を継続的にブログで発信していく予定です:
- 具体的な実装手法と技術スタック
- パフォーマンス最適化のノウハウ
- 実際の業務現場での検証結果
- ユーザーフィードバックと改善プロセス
音声によるAI活用は、ヤマシタの全社員がAIの恩恵を受けるための重要な鍵だと確信しています。
技術的な挑戦は続きますが、現場で本当に使える仕組みを作り上げるため、引き続き検証を進めていきます。
---
【次回予告】技術検証レポート #2
次回は、FishAudioとDifyの具体的な統合方法について、実装の詳細やコード例を交えてお伝えする予定です。
#技術検証レポートで公開しますので、ぜひご期待ください。
執筆者プロフィール:デジタル本部DXシニアマネージャー 道越 安章
2011年神戸大経済卒。関西電力系SIerでB2Bアプリ開発に従事後、PwCコンサルティングではカスタマートランスフォーメーションに所属し業務改革・DXプロジェクトを推進し、「Return on Experience 3」レポートにも参画。20年に東工大MOT修士取得。21年に第一三共に転じ、DX企画部の一員としてバリューチェーン全体のビジネスプロセス変革をテーマに業務可視化・自動化とグローバルCoE立上げを牽引し、トータルケアエコシステムの異業種連携も推進。24年より筑波大MBA‑IB在籍、在宅介護プラットフォーマー構想に共感し25年にヤマシタへ転じ、AIエージェントを活用した次世代ホームケアシステムと新規サービス企画を担当。



