
Release:2025.10.31 Update:2026.03.18
2025年秋。ヤマシタのシステム開発部では、介護用品のレンタルや販売を行うホームケア事業の基幹システムリプレイスという⼤規模プロジェクトが進⾏中です。
外部ベンダー依存から脱却し、事業の根幹を⽀えるシステムを⾃らの⼿で再構築する──その挑戦の最前線に⽴つのが、宮内さんと菅さんの2⼈。
⻑年にわたって外部ベンダーが保守してきた180万⾏という膨⼤なコードベース。 2027年に迫る保守期限。限られた⼈員と時間。これらの制約の中で、彼らはAIエージェントを駆使した⾰新的なアプローチで、不可能と思われた課題に挑みました。
技術責任者の中川さんが司会となり、プロジェクトの全貌からAI活⽤の実際、そして未来への展望までをじっくり聞きました。
簡単な⾃⼰紹介
中川: まずはお⼆⼈の⾃⼰紹介からお願いします。システム開発部でどのような役割を担っているのか、教えてください。
宮内:システム開発部の宮内です。前職では技術リードとして、上場企業で新規事業の⽴ち上げや開発チームの組成、開発プロセスの整備などに携わってきました。現職では、ホームケア事業の基幹システム移⾏に向けた調査と計画策定を担当しています。
実は、私⾃⾝、過去⼤規模な基幹システムの移⾏業務に携わった経験はありませんでした。今回のプロジェクトは、ベンダー様が⻑年保守してきた既存システムを分析し、新しい内製システムへの移⾏計画を作成するという、まさに未知への挑戦でした。
菅:システム開発部の菅です。前職ではエンジニアリングマネージャーとして採⽤‧評価‧育成を含むエンジニア組織のマネジメントを担当しつつ、プロダクト開発をしていました。私も同じく既存コードの解析や移⾏計画策定を担当しています。
システムは約180万⾏ものソースコードで構成されていて、まさに"モノリシックの巨⼈"といった存在です。私は主にAIエージェントのDevinを活⽤した画⾯ベースのコード解析を担当しました。
取り組み概要の説明
中川:まずは、プロジェクトの全体像や背景となる課題を教えてください。
宮内:今回のプロジェクトは、パートナー企業である⼤⼿ベンダー様が⻑年にわたって開発‧保守を⾏ってきた基幹システムに関するものです。
このシステムは当社ホームケア事業全体を⽀えるモノリシック構成の⼤規模アプリケーションで、Java、Pascal、Visual Basicといった複数のプログラミング⾔語で実装されています。⻑年の改修の積み重ねで全体構造が⾮常に複雑になっていました。
菅:私から補⾜すると、実は2つの異なる基幹システムパッケージ──⽣産‧販売管理システムと介護事業者向けの管理システム──を基盤にカスタマイズされた、いわば統合型の巨⼤システムなんです。
重要な制約として、ホームケア事業システムの保守期間が2027年で終了する⾒込みで、延⻑は要交渉という状況があります。
中川:2027年まで、もう時間がありませんね。どのような⽅針で移⾏を進めることにしたんですか?
菅:はい、そこがポイントなんです。「全部作り直してから切り替える」ではなく、ドメイン単位で周辺アプリ等を通して部分的に価値を出しながら移⾏するという⽅針を取りました。
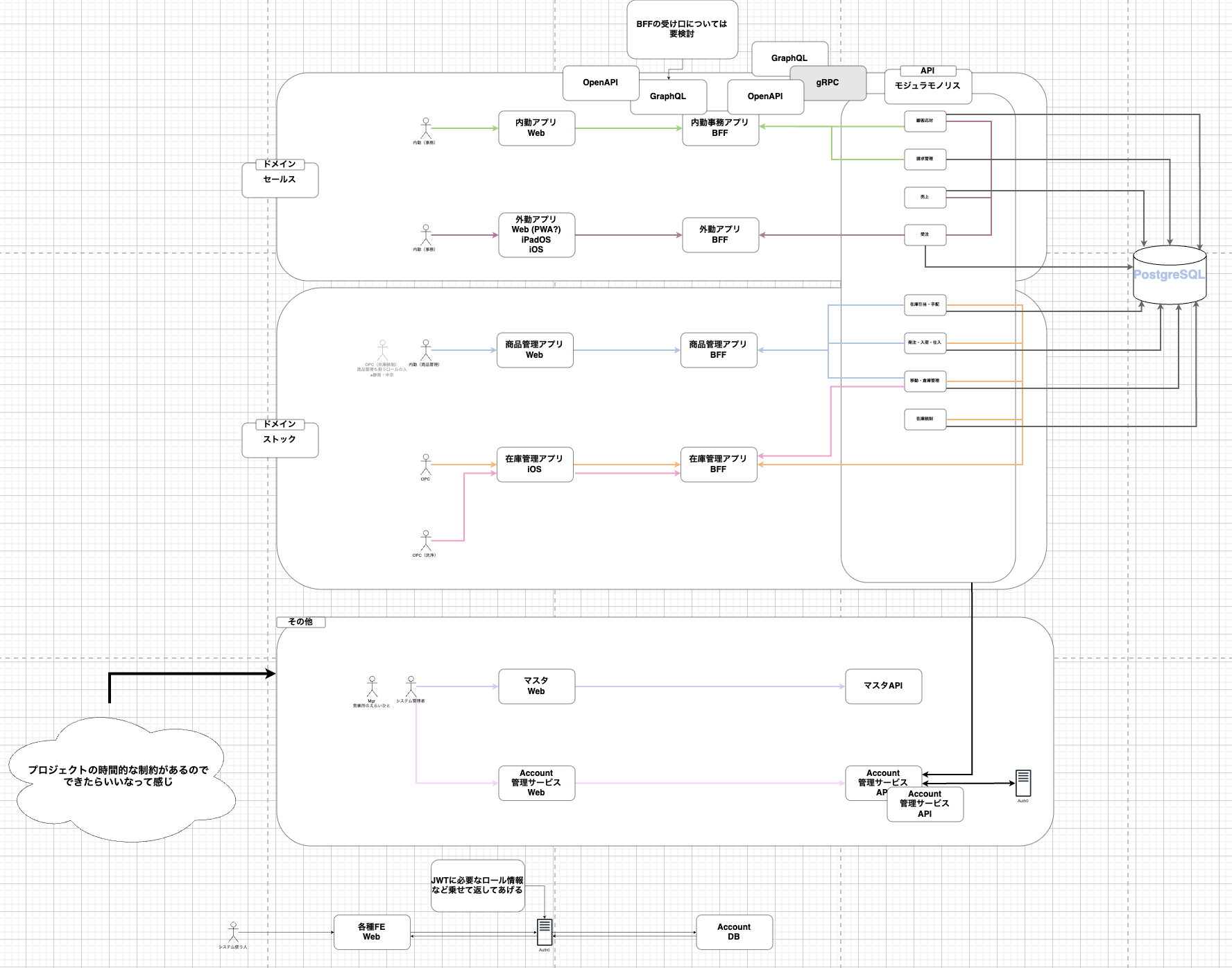
全体のシステムアーキテクチャ図
移⾏パターンの選定にあたっては、複数の候補から検討を重ね、最終的に「ドメインごとに機能がまとまっており、横断依存が⽐較的少ない」パターンを採⽤しました。保守期限が迫っているので、現実的かつ戦略的なアプローチを選んだんです。
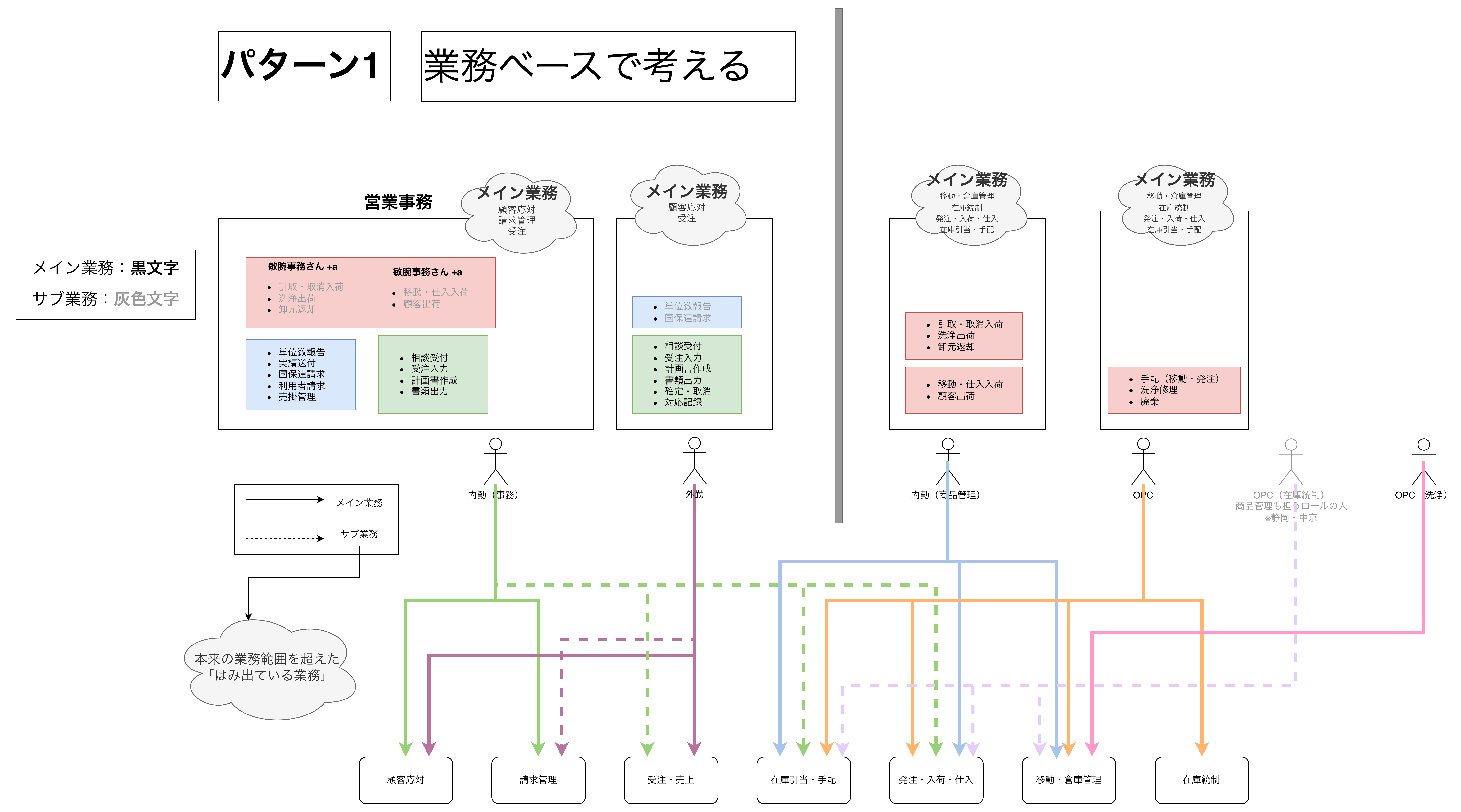
アクターごとにドメイン分割ができないか検討した図
宮内:私も同感です。単なる技術的リプレイスではなく、「どうすれば現場が使いやすいか」「どうすれば10年後も使えるか」という視点からの再設計が必要でした。
当社では、ホームケア事業をさらに推進していくため、この既存システムを新しい内製システムへ移⾏する⽅針を決定しました。その初期ステップとして、ベンダー様に事前資料の共有など多くのご協⼒をいただきながら、現⾏システムの調査を実施しました。
中川:なるほど、時間的制約と技術的複雑性、両⽅の課題を抱えていたわけですね。体制⾯はどうだったんですか?
宮内:実は、並行して開発していた周辺システムのリリース時期の兼ね合いで、対応期間と⼈員に⼤きな制約がありました。メンバーは私と菅さんの2名のみ、期間もおよそ2ヶ⽉という短期間で対応する必要がありました。
通常、数億円規模のシステムリプレイスのための事前調査であれば、より多くの⼈員と余裕のある期間を確保するのが⼀般的かと思いますが、今回は限られた体制と期間の中で成果を出すことが求められました。
何をやったのか
中川:どうやって進めたんですか?
宮内:まずは初期の設計書を読み込み、システム全体の要件や仕様を把握しました。さらに、約10年前に現⾏システムへのリプレイスに携わった当社社員から情報を共有してもらい、当時の設計思想や運⽤経緯についても理解を深めました。
ただ、対象システムのソースコード⾏数は180万⾏と⾮常に多く、全て⼈の⼿で読み込むことは現実的ではありませんでした。そこで、ソースコードの直接の読解は最⼩限に留め、AIを介して処理系の構造や仕様を把握するという⼿法を採⽤しました。
中川:AIの活⽤が鍵だったんですね。菅さんはどのようなアプローチを取られたんですか?
菅:私はAIエージェントのDevinを活⽤した画⾯ベースのコード解析を実施しました。従来のように全コードを読むのではなく、「実際にユーザーが操作する画⾯」から関連コードを辿る⽅式です。
具体的には、Devinセッション内で画⾯のスクリーンショットを添付して、シンプルなコマンドやプロンプトで体系的に解析を進めていきました。
!ask
@GitHubOrganization/生産・販売管理システムリポジトリ @GitHubOrganization/介護事業システムリポジトリ
# ↓ドキュメント生成のためのplaybook呼び出し
!ca_create_doc
# ↓画面単位での解析を実行する
画面:顧客管理 > 利用者状況把握(一覧)
# 添付ファイル
スクリーンショット.png
中川:画⾯ベースというのは⾯⽩いアプローチですね。具体的にDevinはどんな作業を⾃動化してくれたんですか?
菅:Devinが⾃動的に実⾏したのは、以下のような作業です:
1.画⾯名から該当するJSP/テンプレートファイルを特定
2.Controllerクラスの特定と処理フローの追跡
3.ServiceとRepositoryレイヤーの解析
4.データベースアクセスの詳細(CRUD操作)の洗い出し
5.システム間連携ポイントの特定
6.Markdownレポートの⾃動⽣成
このアプローチにより、1画⾯あたり約5分で解析が完了し、約1ヶ⽉で180万⾏を俯瞰できました。250画⾯の解析を約21時間の実作業で完了できたんです。
メリット
# 従来の手法(全コード精読)
・180万行÷1日2,000行読解 = 約895日
# Devin活用
・250画面×5分 = 約21時間の実作業-1ヶ月で完了(レポート作成・レビュー含む)
宮内:私の⽅は、ソースコード解析に加えて、主にER図の作成など、ドキュメントベースの整理や⼯数⾒積を担当しました。ChatGPT、Codex、Claude Code、Cursorを複数使い分けて、AIを"仲間"としてチームに組み込みました。
どういう⼿法をとったのか‧⼯夫したこと
中川:AIを使った解析というのは、かなり先進的ですね。それぞれ⼯夫された点を詳しく教えてください。
菅:最も⼤きな⼯夫は、「画⾯ベースでのソースコード解析」というアプローチです。
従来の「全コードを精読する」⽅法では、180万⾏を1⽇2,000⾏読解すると仮定しても約895⽇かかり、実質的に不可能でした。全コードを読もうとすると2年以上かかる計算なんです。
そこで、「ユーザーが実際に操作する画⾯を起点にした解析」に切り替えました。これによって、死んだコードに時間を費やさず、ビジネス価値に直結する重要な処理だけに集中できたんです。
中川:なるほど、効率的ですね。Devinの活⽤で特に⼯夫した点はありますか?
菅:4つの主要機能を活⽤しました:
1.Knowledgeの活⽤:既存の設計資料‧ER図‧マニュアルをナレッジ化し、⽤語揺れ吸収と関連箇所の想起に使⽤
2.Playbookの活⽤:モジュール解析の定型⼿順(⼊⼝→制御→永続化→外部連携)をレシピ化
3.DeepWiki‧Ask Devinの活⽤:呼び出し関係のサマリ⽣成やテーブル項⽬の役割仮説を⾼速に取得
4.出⼒ブレの調整:System Promptで⽤語定義‧採点基準‧期待する粒度を固定化
ポイントは「AI任せにしない」ということです。AIは曖昧な指⽰には曖昧な結果を返すので、ガードレール設計が極めて重要でした。プロジェクト最初期はDeepWikiとAsk Devinをメインで使っていたのですが、コンテキストが打ち切られるなどの問題がありました。そのためセッション内で !ask 機能を使い調査する⽅式に変更し Playbookにプロンプトを集約した次第です。
宮内:私の⽅では、複数のAIツールを作業特性に応じて使い分けました。おおまかな使い分けですが、PDFやExcelなどのドキュメントデータを元にした資料の⽣成については、ChatGPTを使⽤。ソースコードが絡む作業については、Claude Code、Codex、Cursorを使⽤していました。
菅さんは画⾯ベースの資料作成にDevinを使われていましたが、私は同じ作業でも Claude Codeを使⽤していました。このあたりは、作業のスタイルに応じて、使⽤するAIが⼈により変わるものだなと感じました。
中川:作業の標準化はどのように⾏ったんですか?
宮内:Claude CodeやCursorについては、Claude CodeでいうところのCLAUDE.mdを作成し、⼀定の指針を持って対応していました。
内容としては、複数のプログラミング⾔語を対象とすることが想定されていたので、特定プログラミング⾔語や環境に特化させたスタイルではなく、どのプログラミング⾔語にも対応可能な、抽象的な指針を意識した内容としていました。
菅:プロジェクト進⾏の状況把握のため、1sprint/1weekのスクラムを組んで、遅延リスクを回避したり週次の定例に活⽤していきました。それからスプリントレビューやデイリースクラムを通じてDevinのPlaybookだったりドキュメントの品質だったりを確認してブラッシュアップしていきました。
中川:宮内さんは、ER図の作成でも⼯夫されたと聞きました。詳しく教えてください。
宮内:システムの中⼼となるRDBMS内部の構造を、俯瞰して理解できる資料が存在しなかったことが⼤きな課題でした。
稼働中データベースに存在するテーブル数とコードベースで使⽤されているテーブル数に、かなりの乖離があり、コードベースと設計資料をもとにER図を作成することにしました。コードベース上で使⽤が確認されたテーブルは200件ほどあり、業務ドメインごとに分割された基本設計資料をもとに、それぞれのドメイン領域でのデータ構造を抽出しました。
中川:200テーブルのER図作成は⼤変だったのでは?
宮内:はい、まず実際のSQLファイルと設計資料を照合しながら、対応するテキストベースのER図⽣成ソフトウェア向けのスキーマ定義ファイル (draw.io)を、ChatGPTやCursorを使⽤して作成しました。
ですが、draw.ioでは視認性の観点から、得たい品質のER図が得られませんでした。そこで、表⽰項⽬により細かい調整が加えられるPlantUMLを、ER図の出⼒先として再選定しました。
次のステップとして、draw.io形式のデータからPlantUML形式データへのコンバータを、Cursorを使ってスクラッチで実装しました。オープンソースソフトウェアのコンバータも存在したのですが、要件を完全に満たさなかったので採⽤しませんでした。コンバータというのは⽣成AIが実装が得意なソフトウェアのようで、あまり苦労することなく、⼩⼀時間ほどで要件を満たすコンバータの実装が完了しました。
最終的に業務ドメイン単位ではありますが、データベース内部の構造を俯瞰して確認できるER図を新たに作成することができました。

ER図作成時の作業のフロー
本稿では、180万⾏という膨⼤なコードベースに挑むための基本戦略と、AIを活⽤した⾰新的な解析⼿法についてお伝えしました。
後編では、プロジェクトで直⾯した具体的な課題とその解決策、AIツールの限界と⼈間の判断が必要な場⾯、今後の展望について、さらに深く掘り下げていきます。


